Self confidence amongst many data scientists was radiating in claiming that Brazil would be the ultimate winner and holder of the cup, a dominant prediction into the Croatia-Brazil quarter final face-off. Right before the World Cup started, the above chart (without the red fonts) was shared by the University of Oxford (https://www.oxfordmail.co.uk/news/23134204.oxford-mathematics-researcher-predicts-will-win-world-cup/) and its social media accounts. Even Nature praised the analysis on its website, alluding to the expectations similar to the ones articulated in Micheal Lewis's book Moneyball (https://www.nature.com/articles/d41586-022-03809-y). The red fonts in the above chart highlight the differences versus the predicted results.
A closer look at the model reminds us the aphorism that "all models are wrong." So, what is the most obvious "wrong" in this case? One needs to look at the pillars the model stands on, https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0268511, "it will be assumed that each team scores goals according to an independent Poisson Process, so that Number of goals scored by Team A against Team B ~ Poi(μ A;B)." The odds for each team is calculated as follows by the model (https://www.nature.com/articles/d41586-022-03809-y):
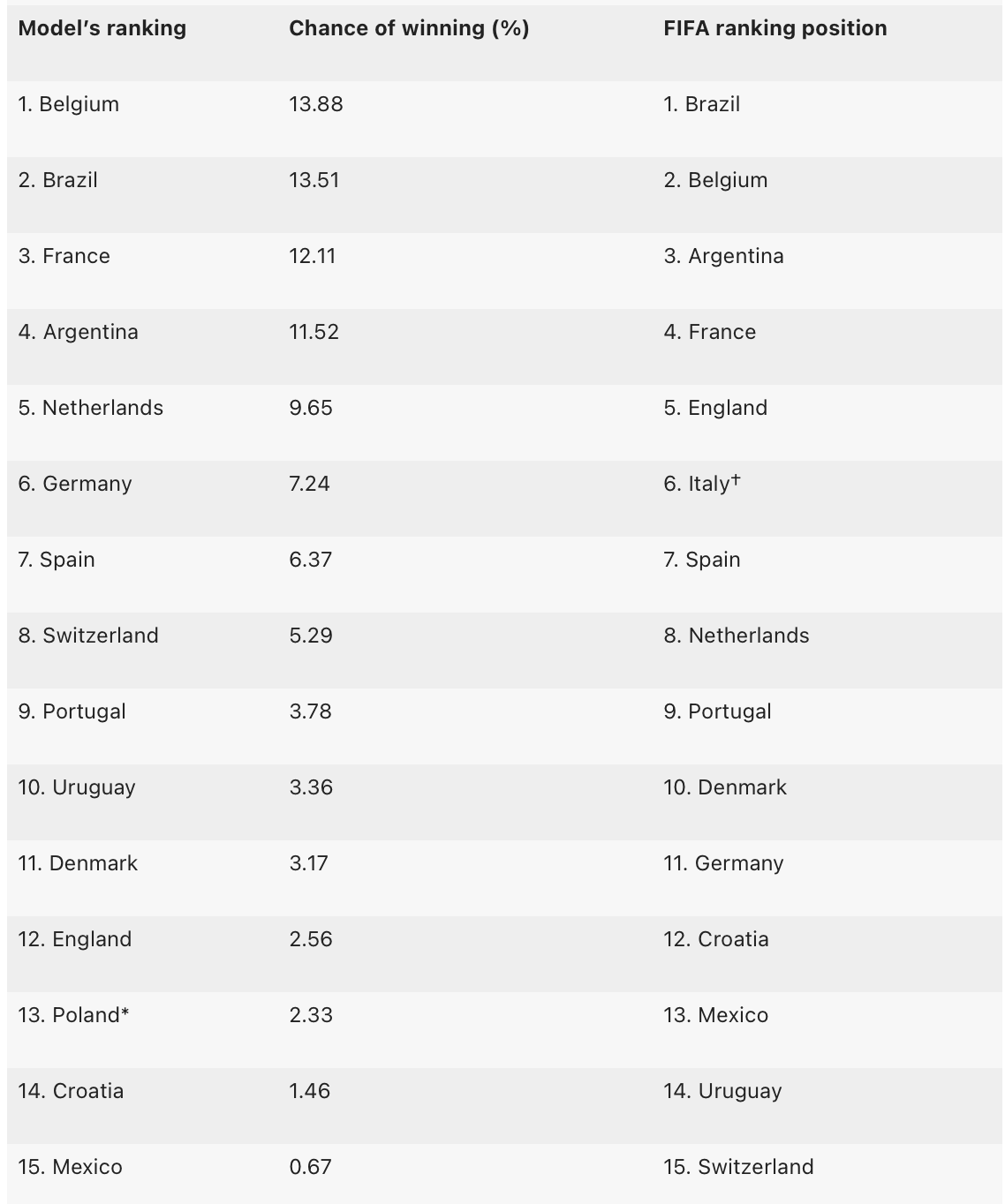
In other words, the independent Poisson process assumes that the previous observation that Croatia became contender against Brazil in QF has no value. The team with one of the lowest odds Croatia (with a chance of 1.46%, see the above table) advancing instead of Spain (6.37% of winning) does not carry any new information for the match against Brazil. If you are earning your life with such bets, it is understandable that you are now angry and hurting.
A major problem with the application of data science in social sciences is that most of the time there is very low external validity. The model provides a good fit with the past observations. In the peer-reviewed publication, it is stated that "it also compares the predictions with the actual results of Euro 2020, showing that they were extremely accurate in predicting the number of goals scored" (https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0268511#pone.0268511.s001). Peddling the model's "effectiveness as a match prediction tool" should have been closely scrutinized before publishing. The editors and referees of the article already allowed for this statement to appear in the publication.Unfortunately, this case of applying-models-in-predicting-real-life-outcomes carries many commonalities and resemblances to the academy's stand on the use of models in social sciences. You can take many models in top journals in management and marketing and experience similar results. Academia is interested in "now-published-what-is-next" attitude, rather than having a skin-in-the-game approach, a criticism frequently shared by Nassim Taleb (https://en.wikipedia.org/wiki/Skin_in_the_Game_(book)).
So how should we adopt or aproach models, especially if one's livelihood depends on it? The aphorism mentioned before actually says "all models are wrong, but some are useful." How can the "useful" be extracted from the "wrongness" of the models? Here are the three principles that should act as the beacon for the future:
- Avoid using static models that do not incorporate most up-to-date information
- Frequently update the predictions as new information becomes available
- Rely on the behavioral observation data (a God's View approach), rather than survey-based data as model inputs
As an example, see https://www.ebrandvalue.com/en/blog/why-traditional-marketing-mix-model-dead-and-how-ebrandvalue-helps/.
eBrandValue Platform'u hakkında daha fazla bilgi edinmek ve hangi metriklerin marka değerini nasıl etkilediğini öğrenmek için aşağıdaki formu kullanarak bize ulaşabilirsiniz.